
Key Takeaways
- Conversion rate optimization compounds as a four-layer operating model—instrumentation, behaviorally sourced hypotheses, experiment discipline, and economic accountability—not as a backlog of isolated page tests 1, 10.
- Tests earn a slot only when sample size is calculated against traffic reality and expected lift, so the program stops shipping noise as wins 3.
- Trust signals and trial-length parameters belong in the prioritization queue alongside copy and form tests, with directional evidence showing extended trials lifted adoption by ~11% and delayed conversion by ~42% 7, 14.
- Coordinate SEO, paid, and lifecycle against one revenue-tied conversion definition and one shared backlog, and rule out hypotheses that cross FTC dark-pattern boundaries before testing 4, 5, 12.
Why most CRO programs plateau at button tests
Most CRO programs stall in the same place: a backlog of headline swaps, CTA color tests, and form-field reorderings that produce small, noisy wins and no compounding effect on pipeline. The work looks busy. The pipeline target does not move.
The diagnosis is rarely creativity. It is structural. Teams treat conversion as a property of individual pages rather than a property of the acquisition system. A paid search team optimizes its landing page against form fills. A content team measures newsletter signups. A lifecycle team owns trial-to-paid. None of them share a hypothesis backlog, a sample-sizing standard, or a definition of what "converted" means at the revenue layer. Tests collide on overlapping traffic, and inconclusive results get shipped as wins.
The research base points in a different direction. Peer-reviewed CRO frameworks for digital commerce treat optimization as a closed loop of measurement, hypothesis generation, controlled experimentation, and operational rollout rather than a tactic library 1. Academic reviews of marketing analytics make the same point at the program level: optimization gains compound when instrumentation, methods, and performance metrics are coordinated, not when individual tests are run in isolation 10. Firms that build digital marketing as a coordinated capability, not a collection of tactics, see the profitability signal show up in the financials 11.
The rest of this article treats conversion rate optimization best practices as an operating model with four layers—instrumentation, hypothesis sourcing, experiment discipline, and economic accountability—and uses the strongest available evidence to specify what belongs in each.
A four-layer operating model for conversion rate optimization
Instrumentation: making the funnel legible before testing it
Before any test runs, the funnel has to be readable. This is the layer most CRO programs skip. Tests get scheduled against pages where the event taxonomy is inconsistent, the channel attribution is broken, and the definition of a qualified conversion drifts between dashboards. The result is statistical noise interpreted as signal.
Instrumentation, in this context, means three things working together: a clean event model that captures the micro-conversions on the path to revenue, channel-level attribution that survives a session break, and a single source of truth for what counts as a conversion at each stage. Academic reviews of data science in digital marketing treat this as the foundation of any optimization work—methods and performance metrics have to be specified before the analysis is meaningful 8.
For a B2B SaaS funnel, that usually means defining events at four checkpoints—landing page engagement, signup form completion, trial activation, and paid conversion—and making sure each event carries the campaign, channel, and content attributes needed to slice results later. If a paid search team and a content team disagree on what "trial start" means, no test on either side will produce a comparable lift number.
A practical test of instrumentation quality: can the team answer, within an hour, what the trial-to-paid rate was last week for organic traffic landing on the pricing page versus paid traffic landing on the same page? If that query requires a week of analyst time and three caveats, the funnel is not yet legible enough to run a defensible experimentation program.
Hypothesis sourcing: behavioral data over aesthetic preference
Once the funnel is legible, the next failure point is where test ideas come from. In most programs, the hypothesis backlog is a mix of stakeholder opinions, competitor screenshots, and whatever a designer flagged in the last review. The hit rate on that backlog is low because the ideas are not grounded in observed behavior.
The CRO framework literature for digital retailers treats hypothesis sourcing as a structured step rather than a creative brainstorm: identify the decision factors that gate conversion at each funnel stage, measure where users drop off, and only then propose changes that target a specific friction point 1. Healthcare website assessment guidance makes the same connection from a different angle—conversion is intertwined with usability, and analytics can augment usability evaluation rather than replace it 2, 6. The behavioral evidence is what makes a hypothesis testable.
For a SaaS funnel, this means sourcing hypotheses from three observable inputs:
- Session recordings or path analysis on the pages where drop-off concentrates
- Support and sales call transcripts that surface objections
- Segment-level analytics that show where one cohort behaves differently from another
A hypothesis like "shortening the signup form will increase trial starts" only earns a test slot when the data shows form abandonment is the actual drop point and the abandoned users match the target ICP.
This discipline does two things. It raises the prior probability that any given test will produce a real lift. And it filters out the aesthetic preferences that consume test capacity without moving pipeline. A hypothesis backlog with twenty behavioral-data-backed entries is more valuable than one with two hundred opinion-backed entries, because the team can defend why each one is in the queue and what it predicts.
Experiment discipline: sample size, power, and shipping fewer false positives
This is where most programs lose money quietly. A test runs for two weeks, shows a 6% lift, gets shipped, and nothing in the revenue numbers changes. The lift was noise, but the team is already three tests further down the backlog and never reconciles the gap.
The NIST/SEMATECH Engineering Statistics Handbook frames experiment design as a sequence of explicit choices: state the hypothesis, define the effect size worth detecting, calculate the sample size needed to detect that effect at a chosen significance level and statistical power, and then run the test long enough to reach that sample 3. CRO programs that skip the sample-size calculation are not running experiments. They are running observations and calling the result a conclusion.
The practical implication for a VP Marketing is that the hypothesis backlog has to be scored against traffic reality before it gets sequenced. A test that needs 80,000 sessions per variant to detect a 5% lift on a page that gets 12,000 sessions a month is a six-month test, not a sprint deliverable. Either the effect size has to be larger to be worth testing, the page has to get more traffic, or the test should be replaced with a qualitative research effort instead.
A prioritization table makes this operational. The columns are hypothesis, target funnel stage, expected lift (with a defensible basis), required sample size per the NIST methodology, weekly traffic to the test surface, and revenue impact expressed as a function of traffic volume, baseline trial-to-paid rate, and CAC. Concrete lift numbers belong in the "expected lift" column only when there is external evidence to anchor them—for example, the randomized field experiment on free trial length found that extending the trial period increased trial adoption by approximately 11% and delayed conversion by approximately 42%, which gives a defensible directional estimate for a trial-duration test in a comparable context 14.
Tests that clear the table get run. Tests that do not clear it get either reframed or removed. The backlog shrinks, but the win rate on what ships rises, and the program stops shipping false positives.
Economic accountability: tying tests to CAC, trial-to-paid, and LTV
The fourth layer is where CRO either earns its budget or quietly loses it. A program that reports micro-conversion lifts—form completions, button clicks, scroll depth—without tying those lifts to CAC, trial-to-paid rate, and LTV is reporting activity, not outcome.
The inbound marketing economic performance literature makes the case directly: optimization actions have to be measured against the cost-result relationship, not against intermediate engagement metrics that may or may not flow through to revenue 9. Broader evidence on digital marketing capabilities reinforces the framing. Firms that build optimization as a coordinated capability tied to financial outcomes show profitability effects beyond what isolated tactics produce 11.
For a SaaS program, economic accountability means three things. Every shipped test is reconciled against the downstream metric it was supposed to move, not just the surface metric it directly affected. A signup form test that lifts form completions by 8% but reduces trial-to-paid rate by 4% is a loss, and the program has to be able to see that within the same reporting view. Tests are sized by expected revenue impact, not by ease of implementation, so that a low-lift test on a high-traffic high-revenue surface beats a high-lift test on a marginal page. And the CRO budget is justified by a quarterly read on pipeline contribution—incremental qualified pipeline attributable to shipped tests, net of any negative downstream effects—rather than by a count of experiments run.
This is the layer that makes CRO defensible to a CFO. Without it, the program is a cost center with a busy dashboard.
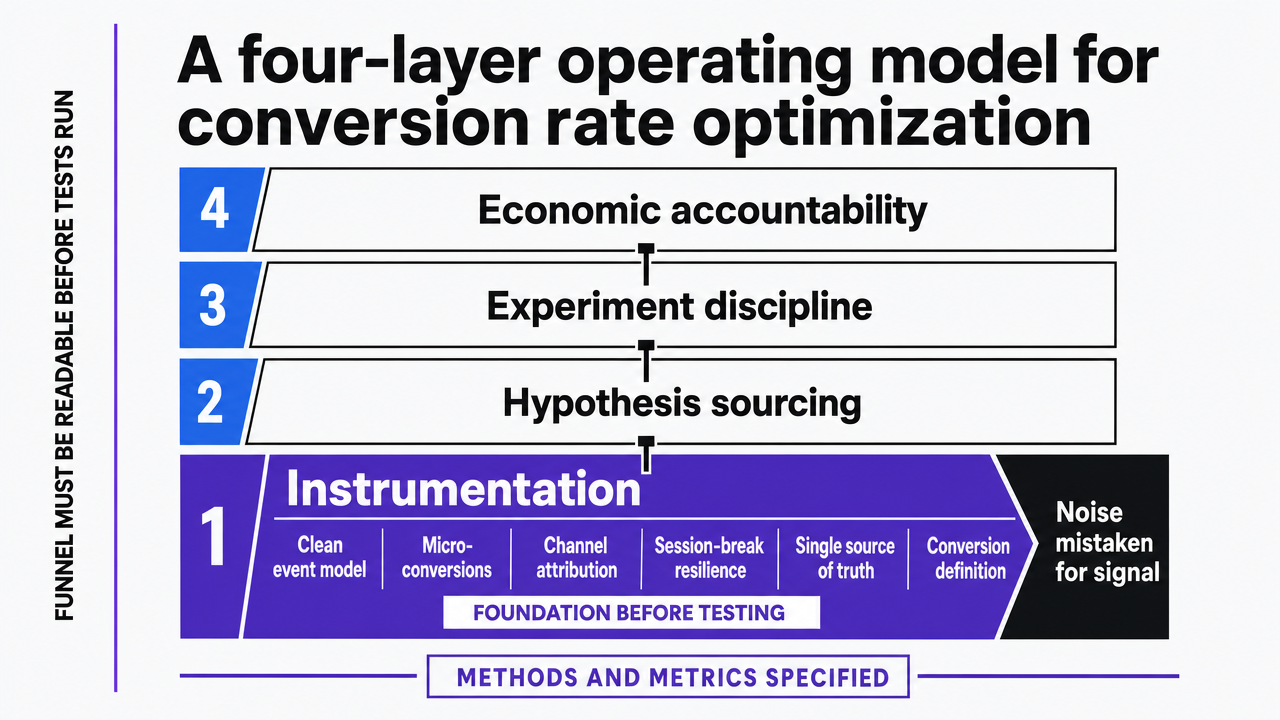 Visualize the four-layer CRO operating model that structures the entire section: instrumentation, hypothesis sourcing, experiment discipline, and economic accountability
Visualize the four-layer CRO operating model that structures the entire section: instrumentation, hypothesis sourcing, experiment discipline, and economic accountability
Trust as a measurable input, not a brand abstraction
Trust gets treated as a brand attribute, which is why most CRO programs never test it. Logos in the footer, a security badge near the credit card form, a customer photo on the pricing page—these get added by instinct and never enter the experimentation queue. The behavioral evidence suggests that is a mistake.
In a peer-reviewed study of consumer responses to green product purchasing, user trust accounted for roughly 57.1% of the variability in conversion outcomes 7. The scope matters: this was a single category-specific study of online green product buyers, not a universal benchmark, and the magnitude will not replicate cleanly in a B2B SaaS funnel. What the finding does establish is that trust-related variables explained more variance in conversion than the design and copy variables that typically dominate CRO backlogs. That is a strong prior for treating trust signals as testable inputs rather than fixed brand decoration.
For a SaaS pricing page or signup flow, the testable trust inputs are concrete:
- Customer evidence placement and specificity—named companies versus anonymized logos, quantified outcomes versus generic testimonials.
- Security and compliance disclosures rendered inline at the form rather than buried in the footer.
- Pricing transparency, including what happens at the end of a trial and how billing is triggered.
- Founder or expert attribution on technical claims.
Each of these is a hypothesis with a defensible behavioral basis, sample-sizable per the methodology in the prior section, and reconcilable against trial-to-paid rather than against form completions alone.
The operational takeaway is simple. Trust signals belong in the same prioritization table as form-field tests and headline changes, scored against the same expected-lift and sample-size criteria. Programs that treat them as a brand decision shipped by a designer skip the test that most often moves the downstream number.
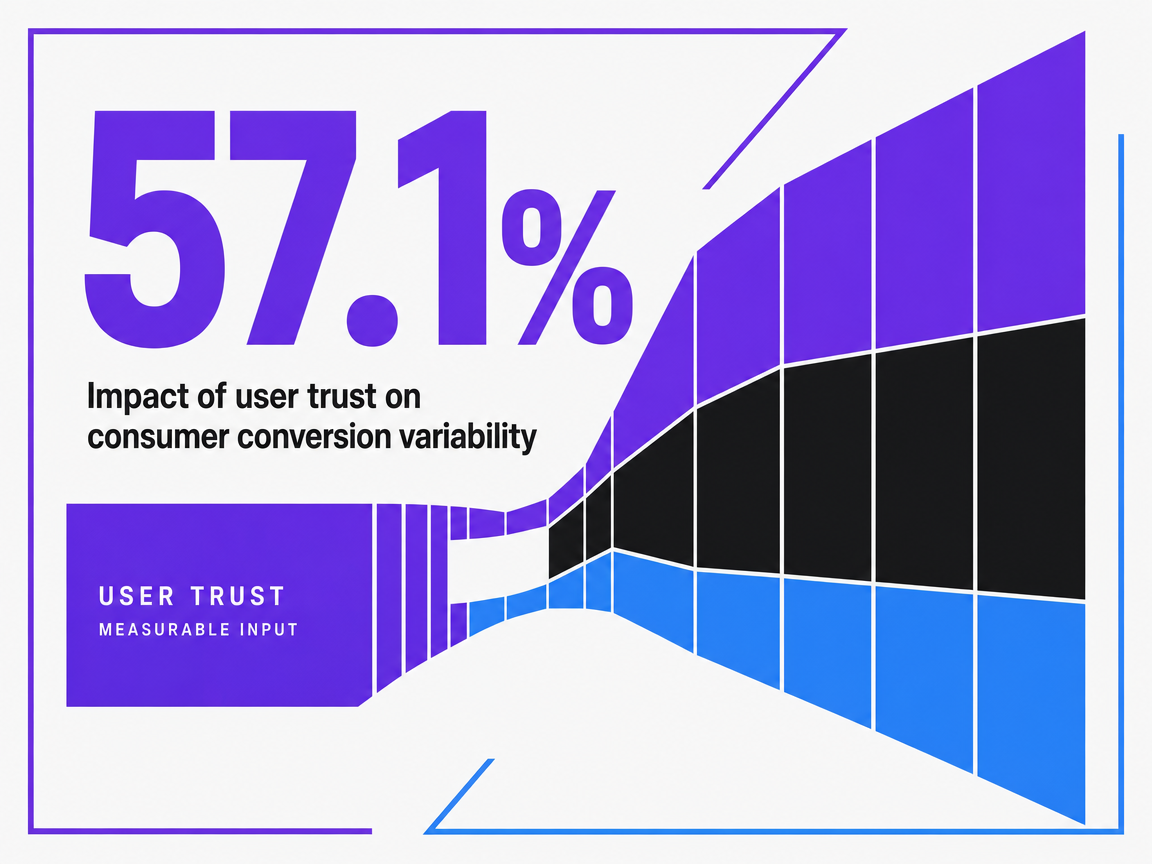 Impact of user trust on consumer conversion variability
Impact of user trust on consumer conversion variability
Impact of user trust on consumer conversion variability
Test CRO improvements with live multi-channel campaigns
Launch and measure real CRO-driven content to validate impact before committing to a full program.
Free trial length as a tested variable in SaaS conversion
Trial length usually gets set by founder intuition and then never revisited. Fourteen days became the default because someone shipped it that way in 2012 and the calendar quarter rolled on. The empirical record suggests the variable is worth putting back on the test queue.
A large-scale randomized field experiment on free trial duration found that extending the trial period increased trial adoption by approximately 11% and lifted delayed conversion by roughly 42% 14. Both numbers come from a controlled experiment rather than an observational benchmark, which is what gives them analytical weight. The directional read is consistent: longer trials lowered the activation barrier for prospects who were hesitant to start, and gave the slower-to-decide cohort enough time to reach the moment where the product proved its value. That is the experimental basis for treating duration as a lever, not a fixed parameter.
The scope caveats matter for a SaaS VP Marketing reading these numbers. The experiment measured trial adoption and downstream conversion, not retention twelve months out or unit economics at the cohort level. A longer trial that lifts paid conversion by 42% on a delayed basis can still erode contribution margin if the additional converters churn faster, if the deferred revenue strains cash, or if the product has a high marginal cost per trial user. The same study notes that optimal trial length is context-dependent and tied to cost structure 14. The number is a prior for designing the test, not a recommendation to ship a 30-day trial tomorrow.
The operational move is to run the test on the team's own funnel with the right downstream metric attached.
- Sample-size the experiment against trial-to-paid rate at the cohort level, not against trial starts, so a lift in adoption that does not survive to paid conversion gets caught.
- Track ninety-day and one-eighty-day retention on the converted cohort to confirm the delayed conversion lift is not just pulling forward customers who churn faster.
- Cap the test variants at durations the finance team has modeled, because a doubled trial length that destroys gross margin is not a CRO win regardless of what the conversion dashboard shows.
The trial-length lever is one of the few SaaS variables with a clean experimental evidence base. That makes it a candidate for an early test slot, not a setting to copy from the study.
Coordinating SEO, paid, and lifecycle against one conversion definition
The hardest CRO problem in a coordinated growth program is not statistical. It is definitional. The SEO team reports conversions as newsletter signups and gated content downloads. The paid search team reports conversions as demo requests. The lifecycle team reports trial-to-paid. Each number is correct inside its own dashboard and wrong as a contribution to pipeline. When three teams optimize against three different conversions on overlapping traffic, the program produces tests that contradict each other and a pipeline read no one trusts.
The large-sample evidence on digital marketing capability points to coordination as the variable that matters. Firms that improve market analytics, pricing, and channel management together capture gains that isolated tactical work does not produce 12. The marketing analytics review literature reaches a parallel conclusion: optimization compounds when measurement and method are coordinated across channels rather than rebuilt separately inside each team 10. The CRO framework literature for digital commerce treats this as a precondition—decision factors and measurement approaches have to be specified at the program level before channel-specific work earns its place in the queue 1.
The operational fix is unglamorous. Pick one revenue-tied conversion definition—for a SaaS program, usually paid activation or first invoice—and make every channel report against it as the primary metric, with channel-specific micro-conversions kept as secondary diagnostics. Maintain a single shared hypothesis backlog across SEO, paid, and lifecycle so that two teams cannot run conflicting tests on the same pricing page in the same week. Reconcile shipped tests in one weekly review where the question is not "did the lift hold on the surface metric" but "did the lift survive to paid conversion when sliced by source channel."
This is also where most in-house teams hit a staffing wall. The work requires a strategist who owns the cross-channel definition, an analyst who can run the reconciliation, and production capacity that does not stall when one role goes on vacation. Platforms like Vectoron exist to compress that coordination layer—running SEO, paid, and conversion work against a single account-level plan rather than three retainers with three dashboards—but the underlying discipline is the same regardless of who executes it: one conversion definition, one backlog, one reconciliation.
See How Unified CRO Execution Yields Statistically Significant Gains
Request a walkthrough of coordinated CRO workflows proven to improve funnel conversion rates by 22% on average for SaaS and multi-location healthcare teams. Review real campaign data, benchmarks, and technical integration examples.
Compliance as the boundary of aggressive experimentation
Aggressive CRO tactics and dark patterns sit on a spectrum, and the line between them is where regulators draw it. The FTC has been explicit about which signup and checkout patterns cross into deception: free trials that convert silently into recurring subscriptions, billing language buried beneath the conversion event, and cancellation flows that bury or block the exit 4. Cancellation friction has drawn its own enforcement attention, with the FTC documenting cases where companies made the unsubscribe process effectively impossible 5.
For a SaaS program optimizing trial-to-paid, this matters operationally. A test that lifts paid conversion by removing a pre-billing reminder, hiding the cancellation link inside an account submenu, or auto-renewing a long trial without explicit consent may produce a clean dashboard win and a regulatory exposure that costs more than the lift returned. The test was not invalid statistically. It was invalid as a business decision.
The practical rule is to set a compliance gate before the prioritization table, not after. Any hypothesis that increases conversion by reducing the user's awareness of what they are agreeing to, or by making reversal harder than commitment, gets removed from the backlog rather than tested. The tests that remain are the ones where lift comes from clarity, reduced friction on legitimate decisions, and better matching of offer to intent. That boundary is also a competitive position—programs that stay inside it accumulate test wins that survive scrutiny, while programs that drift outside it ship lifts that get reversed by legal review or, worse, by a consent decree.
What to build first if your CRO program is starting over
Starting over is a luxury, and it should be spent on the layer that compounds. The sequence that matters is the one the rest of this article describes: instrumentation first, then a behaviorally sourced hypothesis backlog, then experiment discipline, then economic reconciliation. Skipping ahead to test execution is the failure pattern that produces busy dashboards and flat pipeline.
In the first thirty days, a VP Marketing rebuilding the program should ship three things:
- A clean event model that defines landing page engagement, signup, trial activation, and paid conversion with consistent attributes across SEO, paid, and lifecycle.
- One shared conversion definition tied to revenue, with channel-level micro-conversions kept as diagnostics rather than primary metrics.
- A hypothesis backlog scored against traffic-aware sample sizes per established experiment design methodology, so the first tests that ship are statistically capable of producing a defensible result 3.
The first three tests should target the highest-traffic surfaces where behavioral data shows concentrated drop-off, with trust signals and offer structure—including trial parameters where directional experimental evidence exists 14—earning slots ahead of cosmetic changes. That sequence is what platforms like Vectoron are built to compress, but the discipline applies regardless of who runs it.
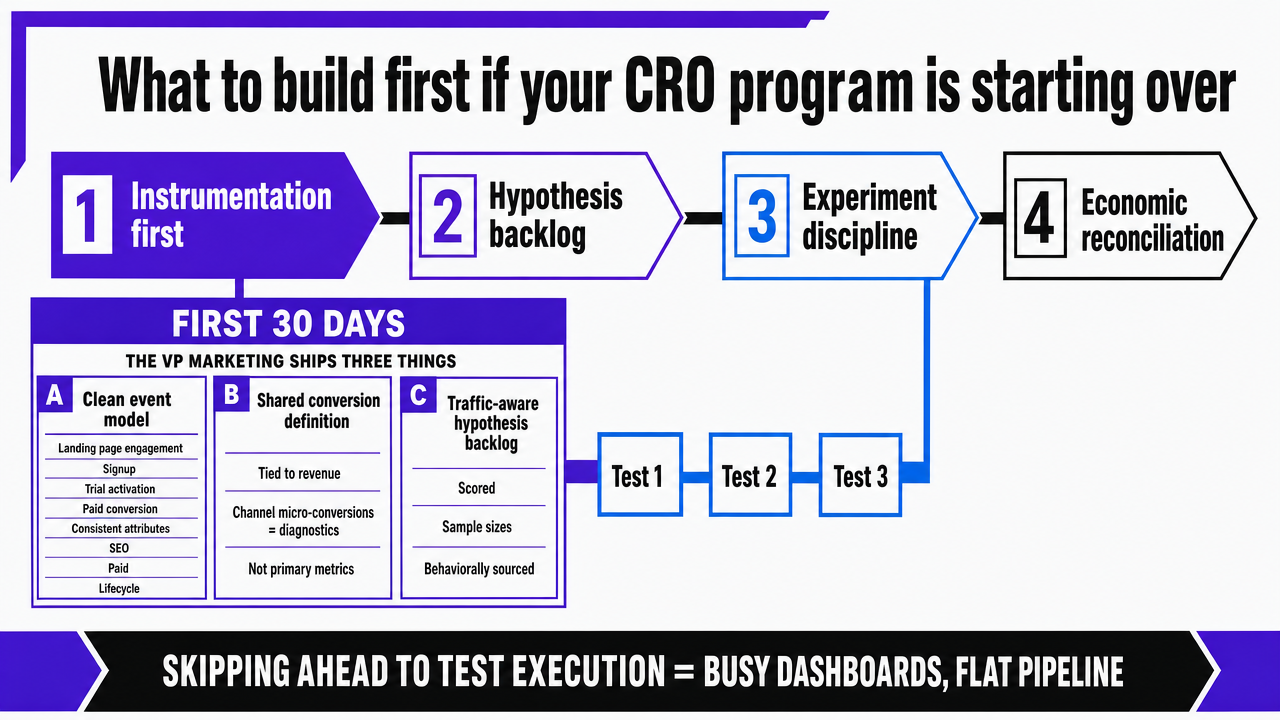 Visualize the 30-day rebuild sequence described in the section: event model, shared conversion definition, and traffic-aware hypothesis backlog, followed by the first three tests
Visualize the 30-day rebuild sequence described in the section: event model, shared conversion definition, and traffic-aware hypothesis backlog, followed by the first three tests
Frequently Asked Questions
References
- 1.Developing a conversion rate optimization framework for digital retailers—case study.
- 2.Methodological Guidelines for Systematic Assessments of Health Websites.
- 3.NIST/SEMATECH Engineering Statistics Handbook.
- 4.How companies manipulate you online – and what the FTC is doing to protect you.
- 5.Tried to cancel a service but couldn't? Learn steps to take.
- 6.Methodological Guidelines for Systematic Assessments of Health Websites.
- 7.Trust and website conversion in consumer responses to green product purchasing.
- 8.Using Data Sciences in Digital Marketing: Framework, methods, and performance metrics.
- 9.Digital inbound marketing: Measuring the economic performance of inbound marketing actions.
- 10.A decade of marketing analytics and more to come: JMA insights.
- 11.The value relevance of digital marketing capabilities to firm profitability.
- 12.How digital technologies reshape marketing: evidence from a large sample.
- 13.Efficient patient care in the digital age: impact of online appointment scheduling on patient satisfaction and practice workflows.
- 14.Longer or shorter? A large-scale randomized field experiment on the length of free trials.